Introducing PCIem
Preface
PCIem exists solely thanks to countless hours of hacking around Linux (And finding out). This is not intended to be a show of any commercial-level framework or anything like that. This should be free knowledge and at no cost for anyone wants to try it.
Author (Me, cakehonolulu) wanted to experiment with how much you can twist the untwistable to get this system working and here's the rants and findings about exactly that process.
First of all, why?
So, aside from the technical challenge fun of it I also was interested on finding a way of developing drivers inside the host directly.
From my limited knowledge, when we try to look at how companies/groups/whoever try to do PCIe driver development it usually goes in 2 possible ways:
1.- They don't care about PCIe
Which is the sanest way. Honestly if you care about you and your teams sanity this is the way to go. Usually involves building a shim or some sort of abstraction layer that avoids the hassle of going down the driver level to do some general useability tests. This is probably sufficient for everything since there's usually ways to attain more low-levelness if needed.
2.- They care about PCIe
This is great if you care about having as much of the development process covered as possible.
Usually requires complex co-simulation/co-emulation models. We're talking multiple-people efforts (Maybe even teams) right here.
Sometimes commercial solutions can be used but guess what, they're pricey.
There's also SimBricks (Which is open-source and works great!) but if you care a bit about speed and not so much about tight timings it can be costly.
Knowing this, I kinda wanted to do the full designing of a simple "dumb framebuffer" PCIe card (That can do zero-copy DMA and whatnot for it's internal "VRAM" in conjunction with the kernel) inside QEMU and get a driver for it; and what a better way of writing a driver than directly on the host.
Yeah, call me crazy.
ProtoPCIem card
So, before actually writing drivers, we need to know our target.
My idea was an early-to-mid-90s PCI card that had a simple state machine for issuing commands to it and maybe some DMA to speed things up a bit.
I came up with the following register file:
0x00 - REG_CONTROL: The main control register for the card; toggling bit 1 (CTRL_RESET) resets the card (Clears status, wipes memory...).
0x04 - REG_STATUS: R/O status register, STATUS_BUSY (Bit 0) if device is busy; STATUS_DONE (Bit 1), last command executed successfully; STATUS_ERROR, well, an error happened with the last command.
0x08 - REG_CMD: The command register, writing here starts a command on the card.
0x0C - REG_DATA: Simple operand for fixed-function operations on the card (Mainly leftover from when designing a much simpler version of PCIem)
0x10 - REG_RESULT_LO: Low 32-bits of the command result register pair. Probably could do single 64-bit one but again, PoC so I did it like this.
0x14 - REG_RESULT_HI: High 32-bits of the command result register pair.
0x20 - REG_DMA_SRC_LO: Low 32-bits of the 64-bit DMA source address of the system memory.
0x24 - REG_DMA_SRC_HI: High 32-bits "" "" "".
0x28 - REG_DMA_DST_LO: Low 32-bits of the destination (As offset within the PCI internal memory).
0x2C - REG_DMA_DST_HI: High 32-bits "" "" "".
0x30 - REG_DMA_LEN: Length in bytes of the DMA transfer.
As for the commands, I have a fixed-function pipeline for now:
CMD_ADD (0x01): Does REG_DATA + 42
CMD_MULTIPLY (0x02): Does REG_DATA * 3
CMD_XOR (0x03): Does REG_DATA ^ 0xABCD1234
RESERVED (0x04)
CMD_DMA_FRAME (0x05): Performs DMA transfer basically
Now that we know the card's definition, I modeled it under QEMU.
 Voodoo 3 PCI card (Voodoo in general served as personal inspiration)
Voodoo 3 PCI card (Voodoo in general served as personal inspiration)
PCIem (or a speedrun on getting Linus mad)
I've been experimenting for a while on how to convince Linux's PCI subsystem functions that there's a PCI device attached to the host bus without one being attached. Sounds crazy but I thought it could be something worth experimenting.
My initial impression was that I would have to go and hack Linux "from within" and have custom kernels and whatnot to have this (Mainly getting rid of sanity checks and whatnot to let this work) but it turns out you can do one trick that'll let you do that from a kernel module w/o ever touching the kernel's source code.
But it turns out you can without touching it at all.
memmap cmdline argument
Turns out you can provide a commandline argument to Linux so that it "reserves" a physical memory chunk from the "System RAM" resource node.
Let's say your /proc/iomem tells you that your "System RAM" node is 0x10000000-0x1FFFFFFF. If we instruct Linux to boot with: memmap=64K$0x1FFEFFFF it'll carve the last 0x10000 and not assign it to "System RAM". This means that we have a "free" and "unused" region we can work with. This is, in part, the root of the mechanism we "exploit" for PCIem.
It turns out that when the PCI subsystem tries to "claim" the region it first checks if it already belongs somewhere (System RAM, other PCI memory...), so by manually carving some of it during boot time we ensure that the PCI subsystem won't complain about it.
I had 2 other ideas to try and get this working before this approach, main one was doing alloc_pages() and crossing my fingers that it'd work (But it didn't).
The second one was much worse, I would manually split one of (If not the only) "System RAM" node at runtime (As dangerous as that sounds) and it'd make the memmap requirement not exist at all; but I won't go into the details of why splicing a "System RAM" node is a bad idea... (It is)
Adding a Synthetic PCIe device
Using pci_scan_root_bus() and having a specially-prepared struct pci_ops with the read and write handlers containing some cool code makes it so that Linux props up a new PCI device on the bus as if it physically existed there.
I also use pci_bus_add_devices() and the pci_bus_assign_resources() to populate the card.
When the kernel probes the new device, it ends up calling those functions on the struct; by carefully setting the parameters, we can specify the PCI device properties. From VENDOR_ID to DEVICE_ID, to extended capabilities, to MSI configuration, DMA... and whatnot.
You can take a closer look on the source code of pciem.c (vph_read_config(), vph_write_config(), vph_fill_config()).
BAR remapping
When we have to back the BAR0 memory we can use the carved region from memmap because when it tries to take ownership of it the PCI subsystem won't complain as it won't see it belonging to "System RAM" and thus won't return "-EBUSY", as we mentioned before.
This enables your usual PCIe driver to do "pci_iomap()" as if nothing.
"ioreadX()" and "iowriteX()" functions also work just fine (Which was kinda expected since it basically works at the memory-barrier levels and whatnot).
This is crucial for driver development as it enables us to make them work.
There's a separate talk on how to handle the different ways of iomap()-ing from the driver (Mainly the uncached, write-combining and all that) and how we could detect those to match the driver but that's for another day (If it even matters, I haven't had the time to actually dwelve into it).
MSIs
For MSIs, what I did was find the assigned synthetic PCIe MSI number and I queued the handler with irq_work_queue(). From the safe(r) kernel context where "pciem_msi_irq_work_func" gets called it just does "generic_handle_irq(num)" which should run all the registered handlers. Which in turn runs the actual PCIe driver's "pci_irq_handler".
So if your hardware registers a pci_irq_handler it'll work here just fine thanks to this.
Based on my testing it's completely indistinguishable from a real, hardware-triggered MSI for the driver; but feel free to try and make it explode :)
DMA
The gist of it is to basically setup a communication flow between the userspace proxy that handles kernel<->proxy<->QEMU transactions so that when actual DMA needs to happen (Writes from and to DMA allocated buffers) everything gets proxied.
The real driver usually does "dma_alloc_coherent()" which returns both a virtual address and a physical address (dma_addr_t).
Those values move across the framework, when QEMU "initiates" the DMA it has to ask PCIem to do the reading from the dma_addr_t (Since we can't do that from userspace...), it effectively proxies the DMA request up to the kernel basically.
PCIem then becomes sort of a "DMA engine"; when the IOMMU is off, we're just a phys_to_virt() call away to be able to copy the data directly to the proxy's "virtual DMA buffer".
If the IOMMU is on, dma_addr_t is an IOVA (I/O Virtual Address), not a physical one. I found out about this doing lots of debugging and observing that the phys address returned by dma_alloc_coherent() being 0xFFFF0000 always (Without amd_iommu=off). Is it some sort of software-controlled trampoline?
Anyhow, for IOVA handling, I had to loop page-by-page for the DMA's len doing iommy_iova_to_phys() to get the IOMMU to handle the translations for me. Then the phys_to_virt() and subsequent copy_to_user().
Handling PCI commands
I had to resort to a poller (Which runs on a kernel thread monitoring for a changed value in the BAR)... yeah, less than optimal but hey, it works!
I've been experimenting with "sequential" ways of handling this, but couldn't figure something that works good enough and doesn't look ugly (I tried memory watchpoints but they apparently don't work on physical addresses which we use for BAR stuff).
pciem_uproxy and pciem's kernel thread
I would go about and explain how I made a model for communication between the userspace component of pciem and qemu and whatnot but I feel like those parts are actually not-so-interesting; you can freely look at the code for some of the stuff I did to try and avoid race conditions (Not sure I fixed them all but it seems stable from what I can see after leaving DOOM running for a few hours).
I'd say this is probably (Alongside the polling) the area that should be improved as it'd let me get rid of much of the code I have, but again; we'll see down the road.
Anyhow, I can get stable output from DOOM and Quake at 640x480@120 (8BPP).
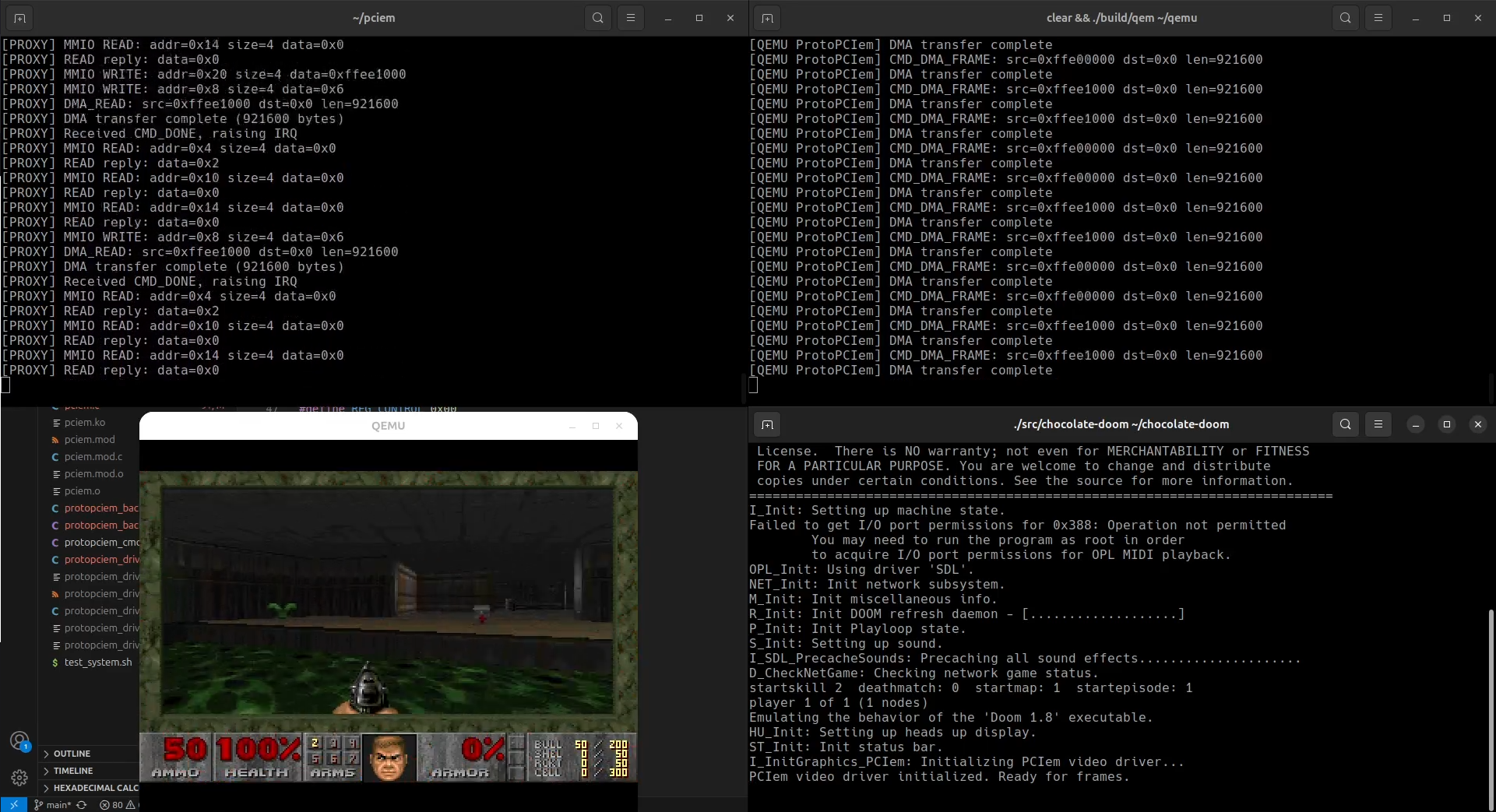 DOOM
DOOM
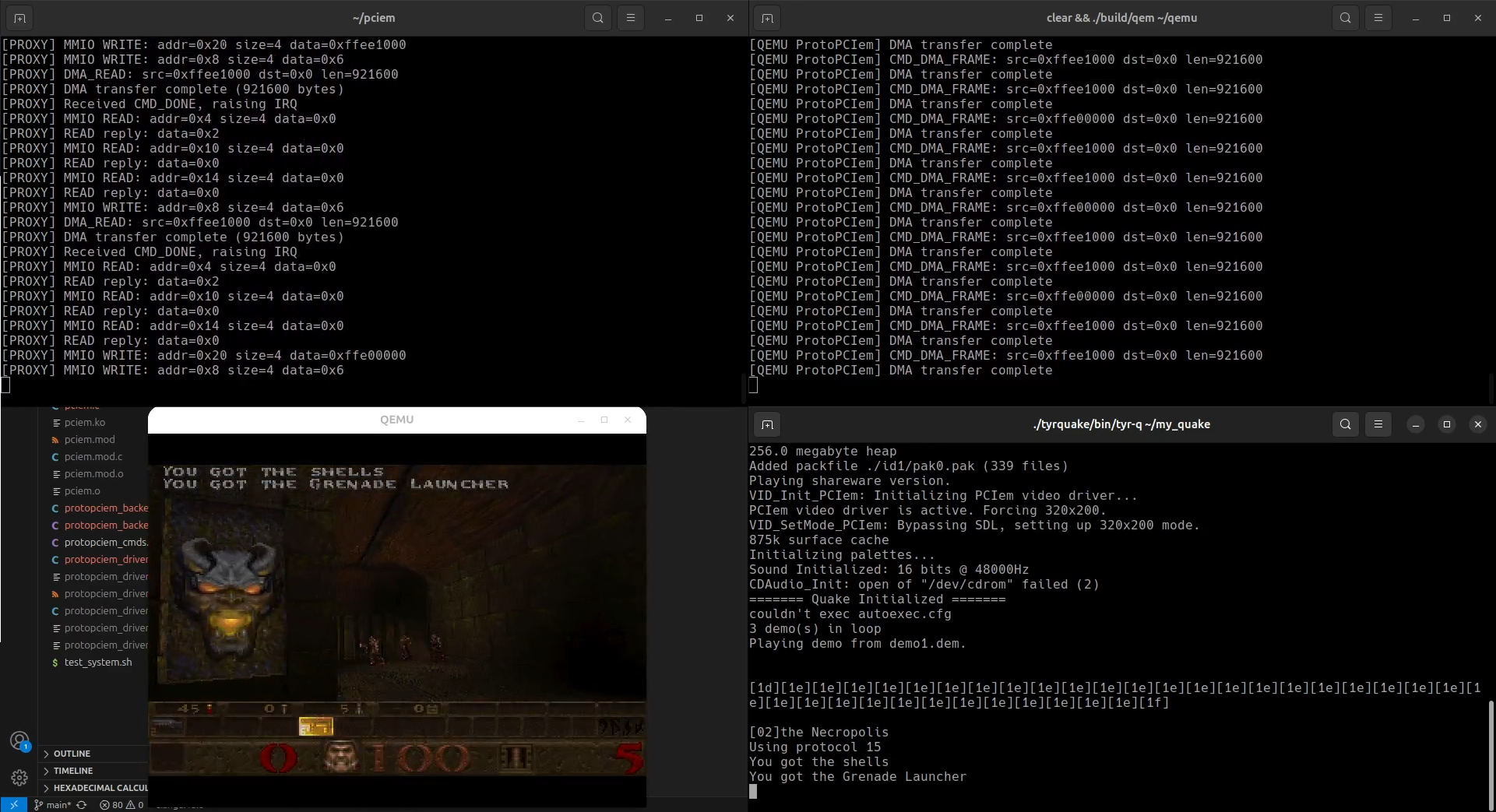 Quake
Quake