Hardware Fastmem 101
 Slightly simplified virtual memory diagram - Courtesy of GeeksForGeeks
Slightly simplified virtual memory diagram - Courtesy of GeeksForGeeks
Preface
The following blog entry is more geared towards enthusiasts who may want to optimize their emulation platform to squeeze some more performance out of it in comparison with more traditional bus designs.
If you already know about the usual ways memory accesses are implemented, you can skip over to Hardware Fastmem.
Refresher for memory access patterns in emulation
When we talk about memory access patterns, what we usually mean is, how the emulator handles (Emulated) memory accesses.
That means, how the target system behaves when it comes to accessing its memory; be it physical memory, virtual memory, I/D Caches, IO...
There are usually a few ways of emulating those, usually memory accesses are delegated to certain opcodes.
On MIPS they're lb/lh/lw/et al for memory loads, sb/sh/sw/et al for stores.
For ARM, ldr/str pairs for loads/stores respectively... and so on for other ISAs.
So, one, has to properly emulate those opcodes and in turn, call the required function to do the access in order for the execution to be successful.
There's 3 "mainstream" ways of handling these accesses.
Ranged accesses
This type of access is usually the most common denominator when it comes to popularity. It tends to be simple, effective, and whilst not super-fast, easy to grasp.
The main idea is to define a predefined amount of memory ranges and use a big if-else chain or a big switch.
Then, based on what each opcode asks for to be accessed, you make the memory handlers check against that value and return the accessed value accordingly:
Code snippet
bus.rs:
// Reads a byte from memory
fn readb(&self, addr: u16) -> u8 {
if addr < 0x2000 {
self.ram[addr as usize]
} else if addr < 0x4000 {
let index = (addr - 0x2000);
self.ppu_registers[index as usize]
} else if addr < 0x4020 {
let index = (addr - 0x4000);
self.apu_io_registers[index as usize]
} else if addr >= 0x8000 {
let index = (addr - 0x8000);
self.rom[index as usize]
} else {
unreachable!();
}
}
// Writes a byte to memory
fn writeb(&mut self, addr: u16, data: u8) {
if addr < 0x2000 {
self.ram[addr as usize] = data;
} else if addr < 0x4000 {
let index = (addr - 0x2000);
self.ppu_registers[index as usize] = data;
} else if addr < 0x4020 {
let index = (addr - 0x4000);
self.apu_io_registers[index as usize] = data;
} else if addr >= 0x8000 {
// ROM is read only
}
}This is for systems that have no MMU, when systems have an MMU, you first have to do the virtual-to-physical address translation to get the physical address so you can properly access the correct memory location.
That means that you may need to emulate enough of the MMU to get it to spew the correct PA's (For MIPS-based consoles, you can usually & the high bits and that gives you the PA due to how they "mirror" memory).
Software fastmem
The main idea behind software fastmem is to have an array of pointers point (duh) whose sole objective is mimicking a page-table structure.
That is, if we were to divide the address space of the target system into pages; we'd have to populate both the read and the write arrays with pointers to page-size-aligned entries (For RAM, scratchpad...).
So, we'd be effectively "mapping" those addresses to our array, simple example (Assuming the pointer array has been built):
Code snippet
bus.rs:
fn sw_readb(&mut self, va: u32) -> u8 {
let page = (va as usize) >> PAGE_BITS;
let offset = (va as usize) & (PAGE_SIZE - 1);
let host = self.page_read[page];
if host != 0 {
unsafe {
(host as *const u8)
.add(offset)
.cast::<u8>()
.read_unaligned()
}
} else {
// IO access
}
}
fn sw_writeb(&mut self, va: u32, value: u8) {
let page = (va as usize) >> PAGE_BITS;
let offset = (va as usize) & (PAGE_SIZE - 1);
let host = self.page_write[page];
if host != 0 {
unsafe {
(host as *mut u8)
.add(offset)
.write_unaligned(value)
}
} else {
// IO access
}
}As you can see, this approach is much, much more faster; since we "delegate" the costly part on startup (The actual filling of the page table arrays for reads/writes) and then we just have to index the corresponding page entry (Else we assume it's unmapped and that means it's usually an IO access for simpler systems or that you may need to update the mappings because a TLB entry was modified f.e.).
There's a great article by wheremyfoodat, on which it explains perfectly how to achieve this system.
So, this already cuts down lots of the cost of memory addressing, but we still have one more trick on our sleeves.
Hardware fastmem
Out of all the methods we've already seen, this one was the most difficult one for me to grasp.
Turns out we can get native-speed (That means, host-level performance) accesses for memory reads/writes for an emulated system.
The way to do this is really tied to what Operating System we want to target and how the emulated system's memory subsystem behaves.
Approach itself should be relatively simple for systems without virtual memory (But you'll have to make some considerations as to how worth it is to implement hardware fastmem for simpler systems), but complexity increases based on how target system memory access patterns (Because one may encounter an MMU and the need to remap memory ranges and that by itself, can become a hassle to do depending on how we tackle it).
This system is also really unsuitable for anything that's not a JIT. Since we kind of need to jump to exception handlers, doing this on a per-memory-access basis will tank our performance, so from now on, we'll assume that this is targeted for a dynamic recompiler-based emulator.
Allocating a virtual memory pool
First and foremost, we need to ask the host operating system for a pool of free and usable virtual memory chunk.
The approach varies between Windows and Linux (Other operating systems may also have its own quirks but won't be covered here) varies.
For instance, under Linux, one would issue a call to mmap():
Code snippet
#[cfg(unix)]
...
let size = ...;
let base = mmap(
ptr::null_mut(),
size,
PROT_NONE,
MAP_PRIVATE | MAP_ANONYMOUS,
-1,
0,
);
...For this specific case, we ask the kernel for a chunk of size, mapped wherever it wants (ptr::null_mut()), initially w/o any access to it (PROT_NONE) and
not backed by a file, we4 also don't specify a file descriptor (-1) since the second flag we specified to mmap() is MAP_ANONYMOUS. Changes are also private to
the process thanks to MAP_PRIVATE.
Thanks to PROT_MODE (Not physically backed with anything) we gain a crucial ability for hardware fastmem (Which we'll explain later), faulting on unmapped accesses.
For Windows, we'll use VirtualAlloc2() (Which means that we'll need version Windows 10 v1803 >=, from 2018) because Windows memory management was bound to 64K alignment
for legacy reasons.
Code snippet
#[cfg(windows)]
...
let size = ...;
let base = unsafe {
VirtualAlloc2(
ptr::null_mut(),
ptr::null_mut(),
size,
MEM_RESERVE | MEM_RESERVE_PLACEHOLDER,
PAGE_NOACCESS,
ptr::null_mut(),
0,
)
};
...Again, ptr::null_mut()'s are, in order, to let the kernel choose the base address, and then so we don't specify extended parameters.
MEM_RESERVE | MEM_RESERVE_PLACEHOLDER, the crucial bit is MEM_RESERVE_PLACEHOLDER, since that's why we use VirtualAlloc2() in the first place.
This creates a reservation that can be split and replaced, working around Windows' legacy 64K allocation granularity that made precise memory layout control impossible with the regular VirtualAlloc().
And then, same as with Linux; PAGE_NOACCESS to make unmapped accesses fault.
For hardware fastmem, placeholders are essential because you need contiguous virtual address space where different regions map to different backing stores (BootROM, RAM, MMIO...) without being constrained by the legacy 64K granularity of the old model.
Adding mappings
To do this under Linux, my way of doing it was using shared memory files. There could be better ways but this one worked for my PS2 Emulator, RustEE.
First, we open a shared memory file:
Code snippet
#[cfg(unix)]
...
let name = c"...";
let fd = shm_open(
name,
OFlag::O_CREAT | OFlag::O_RDWR,
Mode::S_IRUSR | Mode::S_IWUSR,
);
...When we have the file descriptor for it, we truncate the size of the fd itself; we can use ftruncate() for that:
Code snippet
#[cfg(unix)]
...
let fd_size = ...;
ftruncate(&fd, fd_size);
...(Worth noting I'm omitting error handling and stuff not to clutter the post with that).
After this, it's a matter of actually adding the mapping to our "base" pointer of virtual addresses:
Code snippet
#[cfg(unix)]
...
let target = base.add(...);
let map_sz = ...;
let prot = PROT_READ | PROT_WRITE;
mmap(
target as *mut c_void,
size,
prot,
MAP_SHARED | MAP_FIXED,
&fd.as_raw_fd(),
0, /* offset */
);
...This would suffice to have the region mapped. You can also map R/O regions by doing: PROT_READ instead of PROT_READ | PROT_WRITE (Think
BootROMs and such).
If you need to copy a BootROM/BIOS/proprietary binary over the mapping, you can do it by mmap()-ing (Or the Windows alternative) with PROT_READ | PROT_WRITE,
then copying the bytes to it and finally remapping it correctly as R/O (Using mprotect()/VirtualProtect/()):
Code snippet
#[cfg(unix)]
...
let binary: /* Vec<u8> */ ...;
std::ptr::copy_nonoverlapping(
binary.bytes.as_ptr(),
ptr as *mut u8,
binary.bytes.len(),
);
mprotect(ptr, binary.bytes.len(), PROT_READ)?;
...On the Windows side of things, we'll use CreateFileMapping2() to achieve similar results.
Code snippet
#[cfg(windows)]
...
let sz = ...;
let fd = unsafe {
CreateFileMapping2(
INVALID_HANDLE_VALUE,
ptr::null_mut(),
FILE_MAP_READ | FILE_MAP_WRITE,
PAGE_READWRITE,
0,
sz,
/* OsStr */,
ptr::null_mut(),
0,
)
};
...This grants us a memory mapped file.
We then "initialize" the region we'll place the mapping on the pool by issuing a VirtualFree() with a special bit set...
Code snippet
#[cfg(windows)]
let sz = ...;
let addr = ...;
VirtualFree(addr, sz, MEM_RELEASE | MEM_PRESERVE_PLACEHOLDER)
......and we map the fd to the virtual address pool using MapViewOfFile3():
Code snippet
#[cfg(windows)]
let res = unsafe {
MapViewOfFile3(
fd,
GetCurrentProcess(),
base.add(offset) as *const c_void,
0,
sz,
MEM_REPLACE_PLACEHOLDER,
PAGE_READWRITE,
ptr::null_mut(),
0,
)
};
...Again, if you need to copy any proprietary binary to those sections; the approach is similar to that of Linux's.
Handling accesses
Thanks to leveraging the host's MMU we can now do memory accesses as follows:
Code snippet
fn hw_read32(&mut self, addr: u32) -> u32 {
unsafe {
let host_ptr = self.base.add(addr as usize) as *const u32;
*host_ptr
}
}
fn hw_write32(&mut self, addr: u32, val: u32) {
unsafe {
let host_ptr = self.base.add(addr as usize) as *mut u32;
*host_ptr = val;
}
}As you can see, this is a vast improvement in comparison with what we had for previous methods.
Segmentation fault handler
This pretty much covers memory-backed regions (RAM, ROM, Scratchpad...) but, what about IO accesses for instance? Or TLB exceptions that may require actually mapping pages or things akin?
Here come custom signal handlers!
The requisite for a JIT for this is explained now, when catching this faults, one can go and patch the emitted memory access machine code (Proven that it can be easily identified by heuristics in the case of not being the one responsible for the emission, think LLVM IR or Cranelift; or because you know the exact bytes to look for) by the function call to the slower, IO handler.
Imagine your emulator has to wait some time waiting for some IO stuff to happen; for instance, waiting for a VBlank bit on hardware to be untoggled:
-
On a JIT, it'll patch the load instruction with the io handler and subsequent block executions will be just as fast.
-
On an interpreter, each time the load happens it'll jump to the sighandler... and that's a lot of context switching overhead per many times the load happens per second...
General flow
%%{init: { 'themeVariables': { 'fontSize': '20px'}, 'flowchart': {'subGraphTitleMargin': {'bottom': 35}} }}%%
flowchart TD
subgraph JIT ["JIT context"]
A[Machine code] --> B[Memory access]
B --> C[Continue execution]
B --> S[Fault SIGSEGV]
end
subgraph SIG ["Signal handler context"]
S --> D[Retrieve fault address]
D --> E[Retrieve memory access length and type]
E --> F["Patch callsite on JIT (Block) context"]
F --> G[Return to JIT]
end
G --> C
The general idea is to install a signal handler (sigaction() for Linux, AddVectoredExceptionHandler() for Windows) for SIGSEGV (Linux) or look for 0xC0000005 (Windows) exceptions inside the handler.
Signal handler installation
After you enter the signal handler, you can retrieve the faulting address (Linux: (*info).si_addr(), Windows: record.ExceptionInformation[1]) and based on your preferred
method of action, patch the access accordingly.
At this stage, you may want to try and encapsulate the logic to abstract the OSs underneath. Let's assume you have a per-OS structure.
For Linux, we need to install the sighandlers as previously mentioned:
#[cfg(unix)]
extern "C" fn segv_handler(signum: c_int, info: *mut libc::siginfo_t, ctx: *mut c_void) {
let ctx = ctx as *mut ucontext_t;
generic_segv_handler(signum, info, ctx)
}
fn generic_segv_handler(
signum: c_int,
info: *mut libc::siginfo_t,
ctx: *mut H::Context,
) {
...
}
...
fn install_linux_handler() -> Result<()>
...
let handler = SigHandler::SigAction(segv_handler as extern "C" fn(_, _, *mut c_void));
let flags = SaFlags::SA_SIGINFO;
let mask = SigSet::empty();
let action = SigAction::new(handler, flags, mask);
unsafe {
sigaction(Signal::SIGSEGV, &action).map_err(|e| io::Error::new(io::ErrorKind::Other, e))?;
}
...
}And similarly for Windows, but using AddVectoredExceptionHandler() instead:
#[cfg(windows)]
extern "system" fn veh_handler(info: *mut EXCEPTION_POINTERS) -> i32 { unsafe {
generic_segv_handler(info)
}}
fn generic_segv_handler(
info: *mut EXCEPTION_POINTERS
) {
...
}
...
fn install_windows_handler() -> Result<()>
...
let handle = unsafe { AddVectoredExceptionHandler(1, Some(veh_handler)) };
...
}Detecting where and what to patch
The objective inside the sighandler, is to patch the JIT callsite that triggered the access fault.
Whilst there's a few ways of doing so, I chose to have a different set of functions that do the general memory accesses:
hw_read8(), hw_read16(), hw_write32(), hw_write64()... you get the gist.
The main reason as to why I use functions instead of inlining the pointer dereference is mainly because, while you could probably have a trampoline within JIT bounds and take it from there; it felt easier for me, conceptually-speaking; to patch call opcodes instead - so, if the actual pointer dereference fails, we'll be on a "function boundary", that is, it'll have it's own stack frame and such and it'll be easier to identify using less-obscure code; at least, personally speaking.
┌───────────────────────────────────────────┐
│ fn hw_write32 │
│ │
┌─────────────────────────────────────────┐ │ 0x7fff8dc1843df mov eax, [ebp+8] │
│ 0x7fff8dc1843df -> fn hw_write32(...) { │ │ │
│ ... ├───────────►│ │
│ 0x7fff8dc18440e -> } │ │ ... │
└──────────────────┬──────────────────────┘ │ │
│ │ │
│ For all fn hw_xxXX │ inc ecx │
▼ │ add eax, ecx │
┌─────────────────────────────────────────┐ │ mov dword [rdi], eax │
│SavedRanges.push({start, end, "hw_xxXX"})│ │ mov rsp, rbp │
└─────────────────────────────────────────┘ │ pop rbp │
│ 0x7fff8dc18440e ret │
└───────────────────────────────────────────┘
Populate REGISTER_PAIR table with
src=rax
dst=rdi ┌───────────────────────┐ ┌────────────────────────────────────────────────────────┐
│ JIT Context │ │ Signal Handler Context │
├───────────────────────┤ ├────────────────────────────────────────────────────────┤
│ │ │ │
│ JIT Block Execution │ │ Get IP/PC pointing to faulting instruction │
│ │ │ │ │ │
│ ▼ │ ┌──────►│ ▼ │
│ Does memory access │ │ │ Iterate frames backwards │
│ │ │ │ │ │ │
│ ▼ │ │ │ ▼ │
│ Faults │ │ │ Current frame's IP/PC falls between any of SavedRanges?│
│ │ │ │ │
└──────────┬────────────┘ │ └────────────────────────┬───────────────────────────────┘
│ │ │
│ │ ┌────────────┴──────────────────┐
│ │ ▼ ▼
└──────────────────┘ yes no
│ │
│ │
┌────────────▼────────────┐ ┌───────▼────────┐
│We now know memory access│ │Shouldn't happen│
│ type and length │ └────────────────┘
└─────────────────────────┘ What I do on the handler to figure out then to what memory access the one that triggered the fault belongs; is to, at the start of the emulator, I "precompute" the memory ranges of the aforementioned functions (I have a simple array that says: hw_read8() starts X and ends at Y, same for the rest of functions) so it's just a matter of capturing a backtrace of a small amount of frames (After all we should not be much more deep from the original callsite of the JIT) and I check each frame IP against the set of ranges; when I get a match, I immediately know if the access was a read or a write, and the length it tried to use.
For each function of the ones above, I also (At startup) disassemble them with Capstone (I traverse in reverse from the function's ret until I find the register order for knowing which registers I have to get values out of to properly call the IO stub). I have to do this because of Rust's ABI (Or lack threreof).
For x86_64 it's usually a mov reg, (ptr) so it's easy to distinguish what it's trying to write and where. You can get creative, mine is probably the most hacky solution but reliably works. Else you'd have to generate some sort of trampoline code from within the JIT realm that tries to get all of this on runtime which for my case, was a bit more difficult to grasp around.
So I end up building something like:
...
fn init_hw_fastmem(...) -> ... {
...
if let Some(reg) = find_memory_access_register(&cs, *func_ptr, *index) {
REGISTER_MAP[*index] = Some(reg);
}
...
}
fn seghandler(...) {
...
match (access.kind, access.width) {
(Write, B8) => {
let reg_id = REGISTER_MAP[0].expect("no register cached for write8");
let value = H::get_register_value(ctx, reg_id) as u8;
io_write8_stub(addr, value);
}
(Write, B128) => {
let (low_reg, high_reg) = REGISTER_PAIR.expect("no register pair cached");
let low_u64 = H::get_register_value(ctx, low_reg);
let high_u64 = H::get_register_value(ctx, high_reg);
io_write128_stub(bus_ptr, addr, low_u64, high_u64);
}
(Read, B8) => {
let value = io_read8_stub(bus_ptr, addr);
H::set_register_value(ctx, x86_64_impl::X86Register::Rax, value as u64);
}
...
}
}After we have the registers that hold the values that called the function that faulted, we can now proceed to patching. Again, here you can leave your imagination free as in to how to implement this, but what I do is I just get the IP out of the frame that triggered the fault (That means, effectively, the IP that points to the memory access itself) and you patch that. In my case, since it's a movabs+call pattern, I just modify the movabs address for the IO access one instead of the current hw_readX()/hw_writeX(); if you are the one emitting the assembly this is probably super easy because you don't probably need heuristics to patch the call. But since I rely on Cranelift (And usually has different emission of machine code depending on factors unrelated to the topic) I need a tiny tiny bit of heuristics to detect what I have to patch accurately.
A simple, visual example:
JIT Block Prior Patch
┌──────────────────────────────┐
│ mov rax, 1 │
│ xor rbx, rbx │
│ ... │
│ movabs 0x7fff8dc1843df, r11 │
│ call [r11] │
└──────────────────────────────┘
(r11 initially points to *0x7fff8dc1843df* -> hw_write32)After patch:
JIT Block After Patch
┌──────────────────────────────┐
│ mov rax, 1 │
│ xor rbx, rbx │
│ ... │
│ movabs 0x7fff8dca42f14, r11 │
│ call [r11] │
└──────────────────────────────┘
(r11 now points to *0x7fff8dca42f14* -> io_write32)Be wary that you may need to change the permissions of the page where the machine code resides depending on how (Or the JIT framework) handles those before patching.
Returning from the exception
Again, depending on the method, this may be more convoluted (For instance, I initially tried to parse the stack to find the return address of the function for the JIT call and patched it to re-execute the call but that proved to be difficult due to Cranelift not always doing the same pattern for the call to the general memory handler) so I instead opted for doing the first io call myself manually (Thanks to the registers and stuff I mentioned before) and then just return as usual from exception skipping the instruction that failed (So that it doesn't fault again).
Once we have all of this, we're set.
There's a myriad more ways of doing this more sanely probably, but this should get you going :)
Results
Reference:
AMD Ryzen 5 5600G
32 GB RAM DDR4 3200MHz (No XMP, purely JEDEC)With sw_fastmem on my PS2 emulator (Built with --release) I get on the ballpark of 250~ FPSs.
The following image is with hw_fastmem:
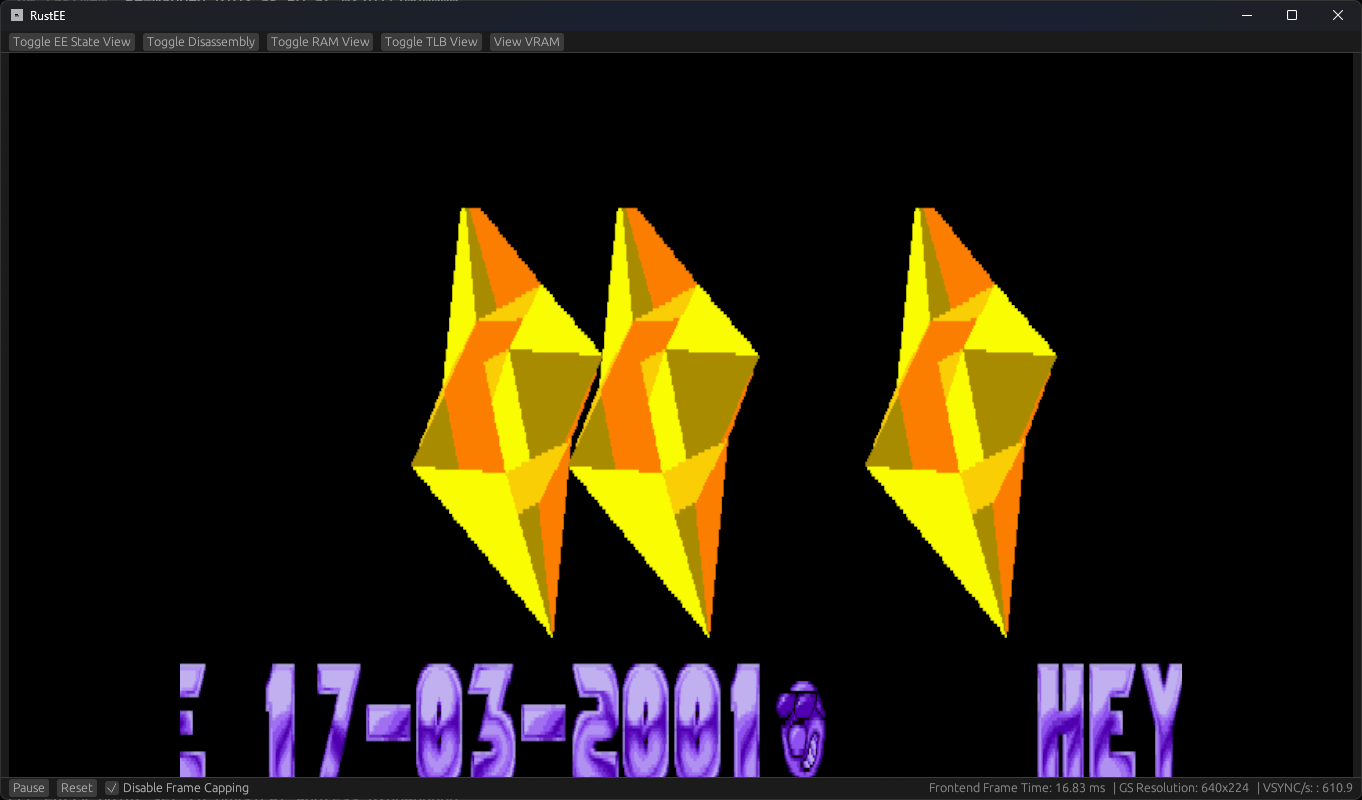 610~ FPSs
610~ FPSs
Pretty worth.